Aged Relic CI/CD Process Update: year-after update
kosar

This is the fourth and final part of the series on updating CI/CD processes. By the way, here’s the table of contents:
- Part 1: What we have, why it’s a problem, planning, and a bit of bash.
- Part 2: TeamCity.
- Part 3: Octopus Deploy.
- Part 4: Behind the scenes. Pain points, future plans, and perhaps an FAQ. Semi-technical.
Currently, we have a fully operational update delivery system that has stood the test of time. You can read about the setup of this system in the first three parts, and now let’s briefly recap what was covered.
We transitioned the CI/CD system from CruiseControl.NET + git deploy to TeamCity + Octopus. Let’s be honest: there was no true CD in the old setup. There might be a separate article about that, but not in this series. A little over a year has passed since the first article was published, and the system has been live in production for about a year and a half. The development process didn’t pause much during the new system’s implementation. There were two code freezes: once when migrating from Mercurial to Git to avoid losing commits, and the other during the production build transition from CCNET to TeamCity (just to be on the safe side).
As a result, we’ve built a system that can optimally deliver updates to all existing environments with minimal time and resource costs, as well as minimal risks.
Since Part 3 was published, there have been some configuration changes worth mentioning.
What Happened This Year
- We almost entirely phased out the “Build + Deploy” configurations. Now, Build and Deploy are separate. The latter are still triggered from TeamCity, but only for ease of use for less-involved team members. It also helps protect Octopus from overly curious minds.
- Fully switched to SemVer. Unfortunately, before DevOps was implemented in the project, there was no talk of SemVer. A snapshot of this versioning was already shown in Part 3, so we won’t dwell on it.
- We gained experience setting up deployments on a server without any access, just with the Octopus agent installed. It’s not that we hadn’t done it before - more like we’d buried that memory as a distant nightmare. Now we had to revisit it. Not the most pleasant experience, but surprisingly tolerable.
- Switched from the Visual Studio (sln) runner to .NET msbuild due to the end of support for the former in TeamCity.
- For the Special Module (see Part 1), we implemented an interesting build call from deployment, with parameter passing through
reverse.dep. - Added a rollback mechanism.
- Reworked the variable sets in Octopus, now using tenant variables.
- Nearly all connection strings were moved out of the repository and into Octopus, to be applied at deployment. Previously, these were stored in the repository.
- Added a protection mechanism for deploying critical modules against accidental tester triggers (more details below).
- Gained seven new tenants (clients).
It sounds impressive, so let’s go over a few of these points in more detail.
Build-Chain Reversed (Point 4)
For the Special Module, as with any other module, there are several environments. The list of pipelines for this module in TeamCity looks like this:
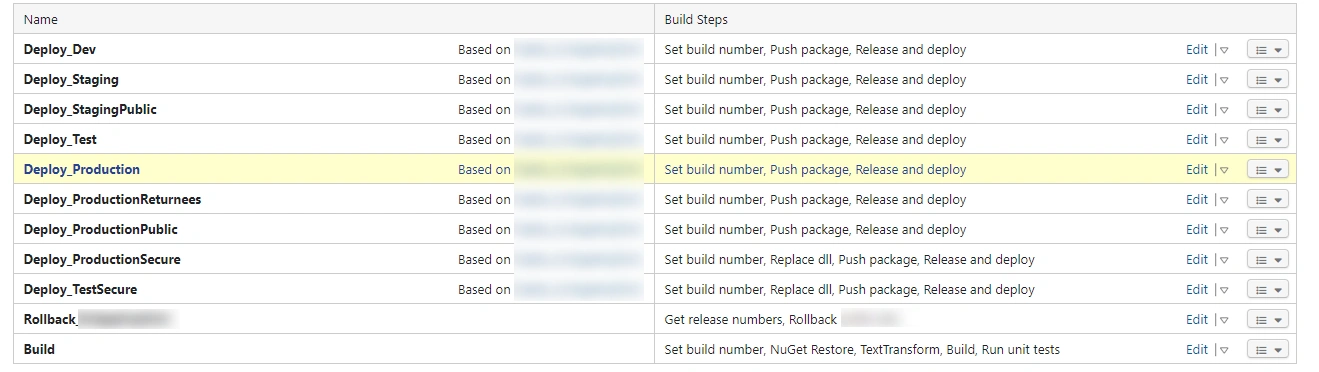
The Build configuration uses a parameterized branch as follows:

This configuration also uses two prompted Select variables: env.Environment and env.buildBranch.
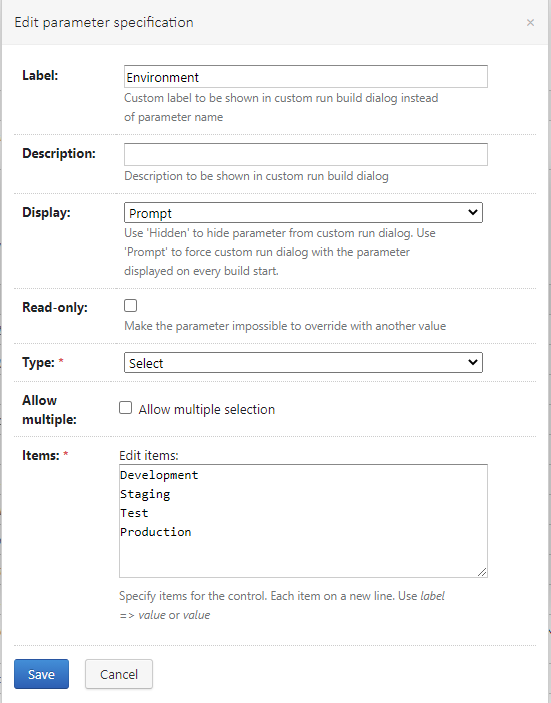
They look nearly identical, differing only in items. Each environment corresponds to a repository branch.
With all the above settings, the manual build launch looks like this:
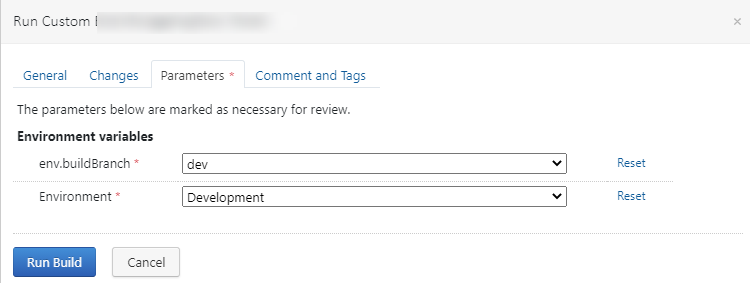
In each Deploy configuration, there’s a dependency on the build configuration’s currency and reverse.dep-type parameters that set env.Environment and env.buildBranch
for Build when it’s triggered. For example, for development, it looks like this:

How it works: when the Deploy button for a particular environment is clicked, any repository changes are checked.
If there are changes, the Build configuration is triggered with reverse.dep variables set. Once the build is complete, the deployment of the new package version is initiated.
Rollback (Point 6)
The rollback process follows this sequence:
- Determine the current and previous release numbers in Octopus for both Core and Module.
- Roll back Core (deploy the previous release).
- Roll back Module.
Octopus retains the last three releases just in case. Rollback in TeamCity only works with the previous release. Rolling back further requires manual intervention, but so far, there’s been no need. Here’s how the versions are determined:
$packageRelease = ((%env.octoExe% list-deployments --server="%env.octoUrl%" --apikey="%env.octoApiKey%" --project="ProjectName.%env.modName%" --environment="%env.Environment%" --outputFormat=json) | ConvertFrom-Json).Version[0..1]
$coreRelease = (((%env.octoExe% list-deployments --server="%env.octoUrl%" --apikey="%env.octoApiKey%" --project="%env.coreProjectName%" --environment="%env.Environment%" --outputFormat=json) | ConvertFrom-Json).Version | Get-Unique)[0..1]
$OctopusPackageCurrentRelease = $packageRelease[0]
$OctopusPackagePreviousRelease = $packageRelease[1]
$corePreviousVersion = $OctopusPackagePreviousRelease | %{ $_.Split('-')[0]; }
$coreEnv = $OctopusPackagePreviousRelease | %{ $_.Split('-')[1]; } | %{ $_.Split('+')[0]; }
$OctopusCoreCurrentRelease = $coreRelease[0]
$OctopusCorePreviousRelease = "$corePreviousVersion-$coreEnv"
Write-Host "##teamcity[setParameter name='OctopusPackageCurrentRelease' value='$OctopusPackageCurrentRelease']"
Write-Host "##teamcity[setParameter name='OctopusPackagePreviousRelease' value='$OctopusPackagePreviousRelease']"
Write-Host "##teamcity[setParameter name='OctopusCoreCurrentRelease' value='$OctopusCoreCurrentRelease']"
Write-Host "##teamcity[setParameter name='OctopusCorePreviousRelease' value='$OctopusCorePreviousRelease']"Rollback is essentially deploying a specific version, so it’s no different from Deploy.2 in Part 2.
The only difference is that instead of latest, it uses %OctopusCorePreviousRelease% and %OctopusPackagePreviousRelease%.
Variable Set Overhaul
Previously, all tenant variables were stored in project configurations and handled by scoping. Here’s a good example from Part 3:
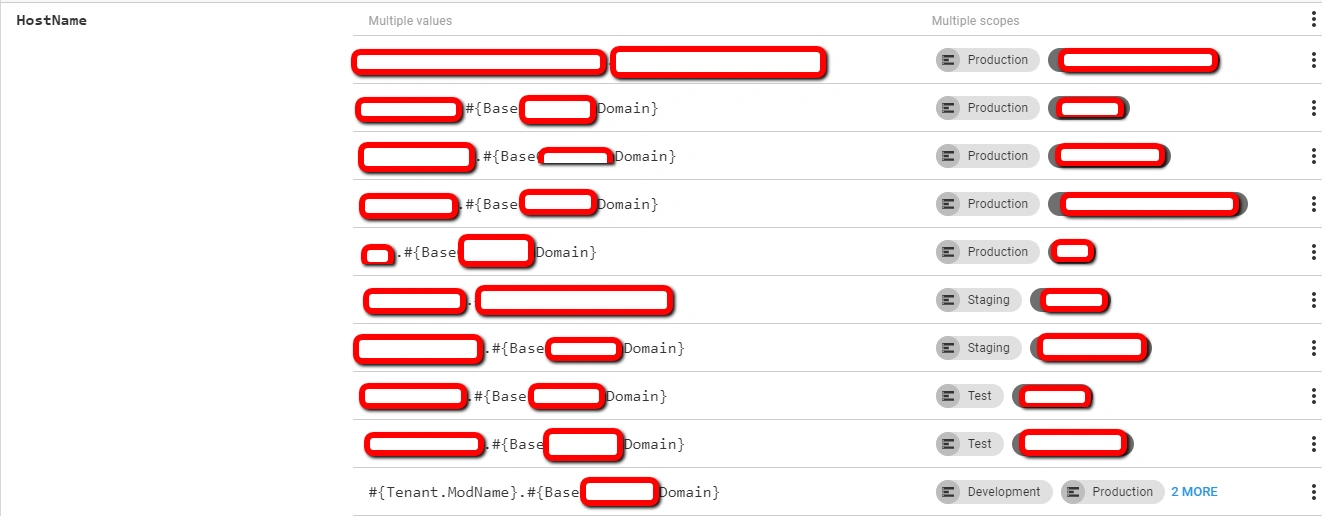
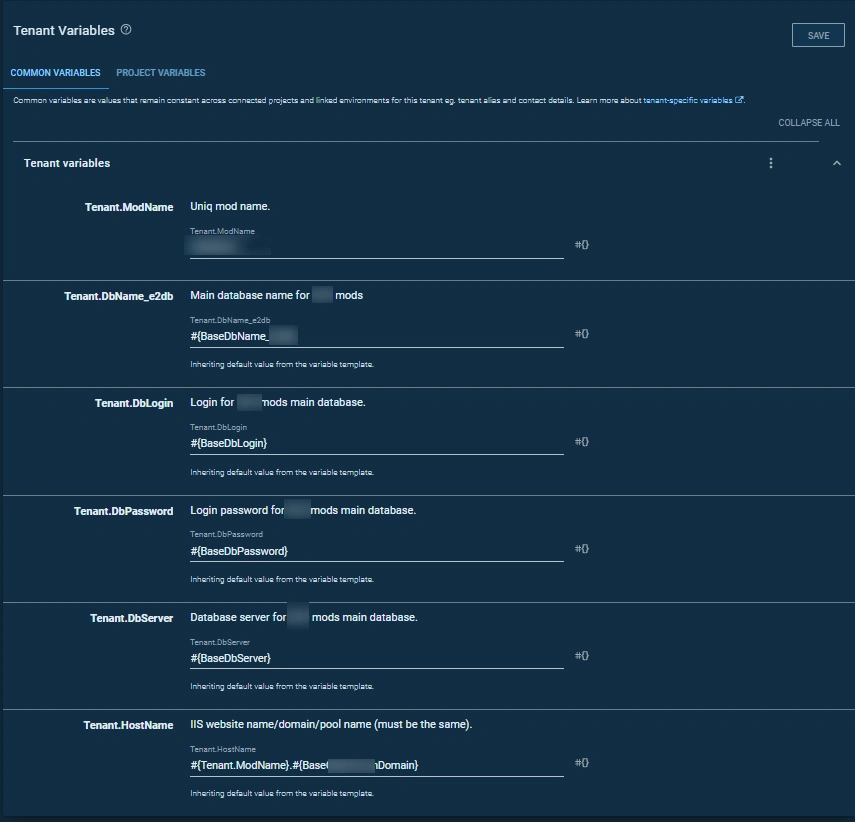
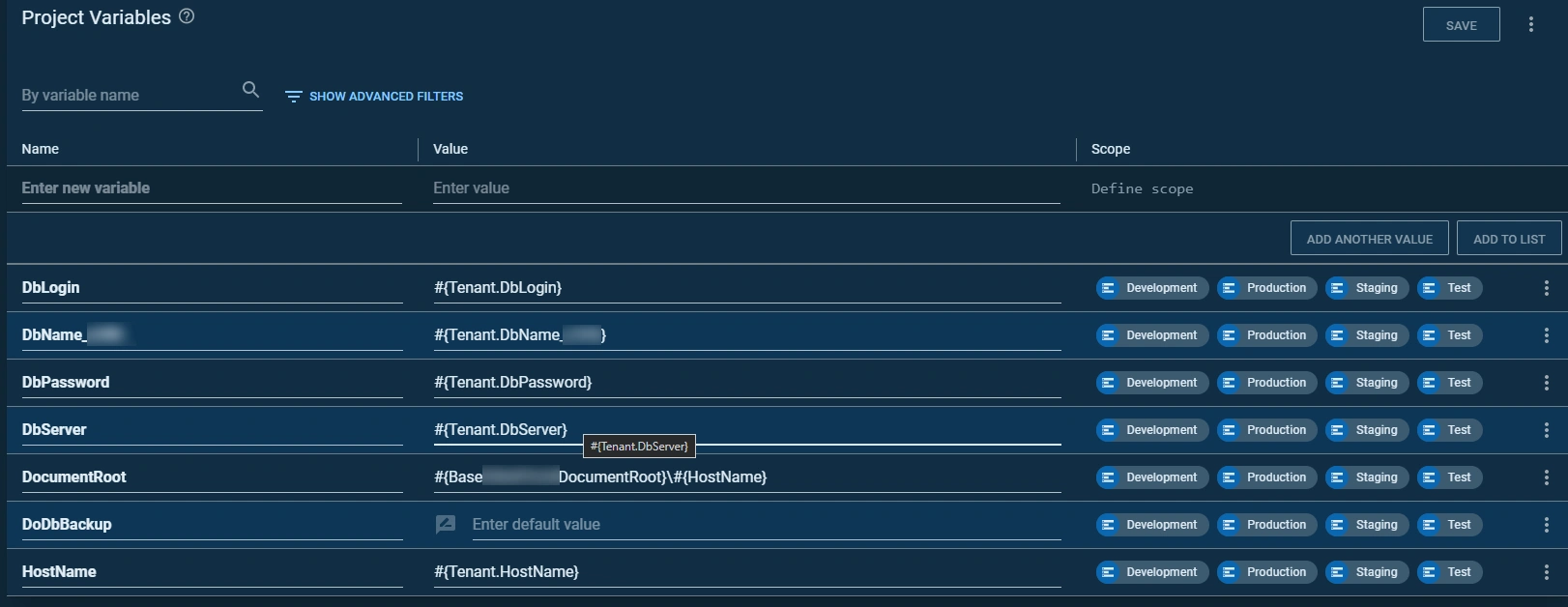
When there are more than three tenants, this setup becomes cumbersome. So, we moved client variables to their designated place—tenant variables within common variables. Now, project variable lists are cleaner and more organized.
Protection Against Testers (Point 9)
Among a tester’s tasks is deploying to certain environments where auto-deploys are restricted. Often, this looks like a rapid series of “click click click click” on Run buttons without much thought. The prod environment is supposed to be an exception, but that’s not always guaranteed. A few incidents led to secure module deployments. These secure modules serve special people who love stability, planned releases, and discussed feature additions. For these modules, a basic safeguard was added: a popup saying, “Are you sure?” with a prompt requiring a typed answer.
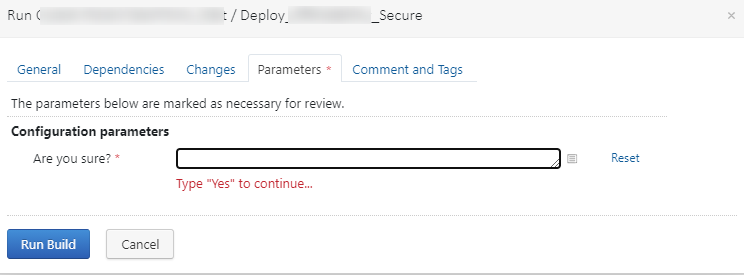
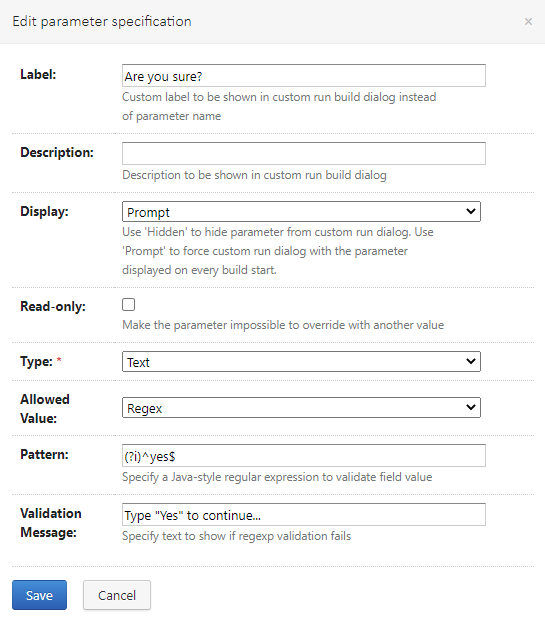
This is implemented using a prompted variable and regexp.
Conclusion
Currently, I’m working on this project minimally. It requires very little support, and it runs almost without my involvement. Some parts are on continuous deployment, while others are limited to delivery. Where manual button-clicking is needed, the tester and lead developer manage it. Adding new configurations (essentially a new client) with a quick functionality check takes about an hour, with time for coffee, no stress. Achieving this with CCNet would have been a fantasy without a massive server resource overhead. Plus, CCNet wasn’t exactly convenient. The endless space shortage problem is gone since there are no redundant copies of the same content on the server. Even rollback has been surprisingly effective.
The project runs smoothly, swiftly, and, most importantly, stably and predictably.
I have no plans to abandon this project, but neither are there any major changes on the horizon. I occasionally glance at Octopus, pleased to see everything functioning without me, as I move on to new projects.
This article turned out to be quite technical. No room left for pain points. Suffice it to say, any negatives stem more from my impressions of Windows and its stack than from the project itself. After all, this was my first Windows stack project. My impressions of the project itself are entirely positive. Despite its legacy roots, it’s a very cool and interesting project. The experience of maintaining and modernizing such a project can genuinely be called invaluable. In short, the world has one more good project with DevOps methodology.